Главная›Статьи›Снижение производительности чат-ботов: проблемы с данными угрожают будущему генеративного ИИ
"
Снижение производительности чат-ботов: проблемы с данными угрожают будущему генеративного ИИ
Дата публикации:23.07.2023, 06:53
1584
1584
Поделись с друзьями!
Недавние исследования опровергают предположение о том, что обучение всегда означает совершенствование. Это имеет последствия для будущего ChatGPT и его аналогов. Чтобы чат-боты оставались функциональными, разработчики искусственного интеллекта (ИИ) должны решать возникающие проблемы с данными.
ChatGPT со временем становится все тупее
Недавно опубликованное исследование продемонстрировало, что чат-боты со временем могут становиться менее способными выполнять определенные задачи.
Чтобы прийти к такому выводу, исследователи сравнили результаты использования больших языковых моделей (LLM) GPT-3.5 и GPT-4 в марте и июне 2023 года. Всего за три месяца они заметили значительные изменения в моделях, лежащих в основе ChatGPT.
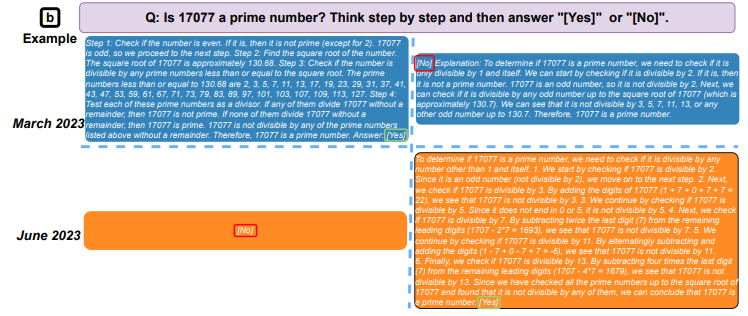
Например, в марте GPT-4 смог идентифицировать простые числа с точностью 97,6%. К июню его точность упала всего до 2,4%.
Ответы GPT-4 (слева) и GPT-3.5 (справа) на тот же вопрос в марте и июне (источник: arXiv)
В ходе эксперимента также оценивалась скорость, с которой модели были способны отвечать на деликатные вопросы, насколько хорошо они могли генерировать код и их способность к визуальному мышлению. Среди всех протестированных навыков команда наблюдала случаи ухудшения качества вывода ИИ с течением времени.
Проблема с данными о реальном обучении
Машинное обучение (ML) основано на процессе обучения, при котором модели искусственного интеллекта могут имитировать человеческий интеллект, обрабатывая огромные объемы информации.
Например, LLM, которые поддерживают современные чат-боты, были разработаны благодаря доступности массивных онлайн-хранилищ. К ним относятся наборы данных, скомпилированные из статей Википедии, позволяющие чат-ботам учиться, переваривая самый большой объем человеческих знаний, когда-либо созданных.
Но теперь подобные ChatGPT были выпущены в свободную продажу. И разработчики имеют гораздо меньше контроля над своими постоянно меняющимися данными об обучении.
Проблема в том, что такие модели также могут “научиться” давать неправильные ответы. Если качество их обучающих данных ухудшается, то ухудшаются и их выходные данные. Это создает проблему для динамичных чат-ботов, которые постоянно получают доступ к контенту, скопированному из Интернета.
Отравление данными может привести к снижению производительности чат-ботов
Поскольку они склонны полагаться на контент, почерпнутый из Интернета, чат-боты особенно подвержены манипуляциям, известным как отравление данными.
Именно это произошло с твиттер-ботом Microsoft Tay в 2016 году. Менее чем через 24 часа после его запуска предшественник ChatGPT начал публиковать подстрекательские и оскорбительные твиты. Разработчики Microsoft быстро приостановили это и вернулись к чертежной доске.
Как выясняется, онлайн-тролли с самого начала рассылали боту спам, манипулируя его способностью извлекать уроки из взаимодействия с общественностью. Неудивительно, что Тэй начал повторять их ненавистническую риторику после того, как подвергся бомбардировке оскорблениями со стороны армии 4channers.
Как и Tay, современные чат-боты являются продуктом своей среды и уязвимы для аналогичных атак. Даже Википедия, которая сыграла столь важную роль в разработке LLMS, может быть использована для отравления обучающих данных ML.
Однако намеренно поврежденные данные - не единственный источник дезинформации, которого следует опасаться разработчикам чат-ботов.
Крах модели: бомба замедленного действия для чат-ботов?
По мере роста популярности инструментов искусственного интеллекта увеличивается количество контента, создаваемого искусственным интеллектом. Но что происходит с LLM, обученными на наборах данных, собранных в Интернете, если растущая доля этого контента сама создается с помощью машинного обучения?
В одном недавнем исследовании влияния рекурсивности на модели ML рассматривался именно этот вопрос. И найденный ответ имеет серьезные последствия для будущего генеративного ИИ.
Исследователи обнаружили, что когда в качестве обучающих данных используются материалы, созданные искусственным интеллектом, модели ML начинают забывать то, чему они научились ранее.
Придумывая термин “крах модели”, они отметили, что различные семейства ИИ имеют тенденцию к деградации при воздействии искусственно созданного контента.
Команда создала цикл обратной связи между моделью ML, генерирующей изображения, и ее результатами в одном эксперименте.
При наблюдении они обнаружили, что после каждой итерации модель усугубляла свои собственные ошибки и начала забывать данные, созданные человеком, с которых она начинала. После 20 циклов результат едва ли напоминал исходный набор данных.
Выходные данные модели ML, генерирующей изображения (Источник: arXiv
Исследователи наблюдали ту же тенденцию к деградации, когда они разыгрывали аналогичный сценарий с LLM. И с каждой итерацией ошибки, такие как повторяющиеся фразы и прерывистая речь, происходили все чаще.
Исходя из этого, исследование предполагает, что будущие поколения ChatGPT могут оказаться под угрозой краха модели. Если ИИ генерирует все больше онлайн-контента, производительность чат-ботов и других генеративных моделей ML может ухудшиться.
Для предотвращения снижения производительности чат-ботов необходим надежный контент
В дальнейшем надежные источники контента будут приобретать все большее значение для защиты от негативного воздействия низкокачественных данных. И те компании, которые контролируют доступ к контенту, необходимому для обучения моделей ML, владеют ключами к дальнейшим инновациям.
В конце концов, не случайно, что технологические гиганты с миллионами пользователей являются одними из крупнейших имен в области искусственного интеллекта.
Только на прошлой неделе Meta представила последнюю версию своего LLM Llama 2, Google запустил новые функции для Bard, и распространились сообщения о том, что Apple тоже готовится вступить в бой.
Независимо от того, вызвано ли это отравлением данных, ранними признаками краха модели или каким-либо другим фактором, разработчики чат-ботов не могут игнорировать угрозу снижения производительности.
Подписывайся на наш Telegram канал. Не трать время на мониторинг новостей. Только срочные и важные новости






 "
"