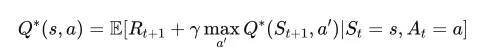Это была история корпоративного шпионажа, которую даже настоящий сценарист-человек не смог бы придумать. OpenAI, которая вызвала глобальную одержимость искусственным интеллектом в прошлом году, попала в заголовки газет после внезапного увольнения и возможного восстановления в должности Сэма Альтмана, генерального директора компании.
Даже после того, как Альтман вернулся к тому, с чего начинал, остается клубящееся облако вопросов, включая то, что происходило за кулисами.
Некоторые описывали хаос как битву уровня HBO в “Преемственности" или “Игре престолов”. Другие предположили, что это произошло из-за того, что Альтман переключил свое внимание на другие компании, такие как Worldcoin.
Но последняя и наиболее убедительная теория гласит, что его уволили из-за одной буквы: Q.
Неназванные источники сообщили Reuters, что технический директор OpenAI Мира Мурати заявила, что крупное открытие, описанное как “Q Star” или “Q * ”, послужило толчком к иску против Альтмана, который был осуществлен без участия председателя правления Грега Брокмана, который впоследствии ушел из OpenAI в знак протеста.
Что такое "Q *" и почему нас это должно волновать? Все дело в наиболее вероятных путях, по которым может пойти развитие ИИ.
Раскрываем тайну Q*
Загадочный Q *, процитированный техническим директором OpenAI Мирой Мурати, привел к безудержным спекуляциям в сообществе искусственного интеллекта. Этот термин может относиться к одной из двух различных теорий: Q-learning или алгоритму Q * из Мэрилендской системы опровержения доказательств (MRPPS). Понимание разницы между этими двумя понятиями имеет решающее значение для понимания потенциального влияния Q *.
Теория 1: Q-Learning
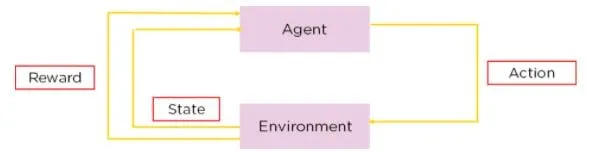
Q-learning - это разновидность обучения с подкреплением, метод, при котором ИИ учится принимать решения методом проб и ошибок. В Q-learning агент учится принимать решения, оценивая “качество” комбинаций действий и состояний.
Разница между этим подходом и текущим подходом OpenAI, известным как обучение с подкреплением посредством обратной связи с человеком или RLHF, заключается в том, что он не полагается на взаимодействие с человеком и делает все самостоятельно.
Представьте робота, ориентирующегося в лабиринте. С помощью Q-learning он учится находить кратчайший путь к выходу, пробуя разные маршруты, получая положительные вознаграждения, установленные его собственным дизайном, когда он приближается к выходу, и отрицательные вознаграждения, когда заходит в тупик. Со временем, методом проб и ошибок, робот разрабатывает стратегию ("Q-таблицу"), которая подсказывает ему наилучшее действие из каждой позиции в лабиринте. Этот процесс является автономным и зависит от взаимодействия робота с окружающей средой.
Если бы робот использовал RLHF, вместо того, чтобы выяснять ситуацию самостоятельно, человек мог бы вмешаться, когда робот достигнет перекрестка, чтобы указать, был ли выбор робота мудрым или нет.
Эта обратная связь могла быть в форме прямых команд ("поверни налево"), предложений ("попробуй путь с большим освещением") или оценок выбора робота ("хороший робот" или "плохой робот")
В Q-learning Q * представляет желаемое состояние, в котором агент точно знает, какое действие лучше предпринять в каждом состоянии, чтобы максимизировать общее ожидаемое вознаграждение с течением времени. В математических терминах он удовлетворяет уравнению Беллмана.
Еще в мае OpenAI опубликовала статью, в которой говорилось, что они "обучили модель достигать нового уровня в решении математических задач, вознаграждая каждый правильный шаг рассуждений вместо простого вознаграждения за правильный окончательный ответ". Если бы они использовали Q-learning или аналогичный метод для достижения этой цели, это открыло бы целый ряд новых проблем и ситуаций, которые ChatGPT смог бы разрешить изначально.
Теория 2: Алгоритм Q * от MRPPS
Алгоритм Q * является частью системы процедур опровержения доказательств Мэриленда (MRPPS). Это сложный метод доказательства теорем в ИИ, особенно в системах вопросов-ответов.
“Алгоритм Q * генерирует узлы в пространстве поиска, применяя семантическую и синтаксическую информацию для направления поиска. Семантика позволяет завершать пути и исследовать плодотворные пути”, - говорится в исследовательском документе.
Изображение: Джек Минкер
Один из способов объяснить этот процесс - рассмотреть вымышленного детектива Шерлока Холмса, пытающегося раскрыть сложное дело. Он собирает улики (семантическую информацию) и логически связывает их (синтаксическую информацию), чтобы прийти к выводу. Алгоритм Q * работает аналогично в искусственном интеллекте, комбинируя семантическую и синтаксическую информацию для навигации по сложным процессам решения проблем.
Это означало бы, что OpenAI на шаг приблизился к созданию модели, способной понимать реальность за пределами простых текстовых подсказок и в большей степени соответствующей вымышленным J.A.R.V.I.S (для GenZers) или компьютеру Bat (для boomers).
Итак, в то время как Q-learning - это обучение ИИ извлекать уроки из взаимодействия с окружающей средой, алгоритм Q больше предназначен для улучшения дедуктивных возможностей ИИ. Понимание этих различий является ключом к оценке потенциальных последствий “Q” OpenAI. Оба варианта обладают огромным потенциалом в развитии искусственного интеллекта, но их применение и последствия существенно различаются.
Все это, конечно, всего лишь предположения, поскольку OpenAI не объяснила концепцию и даже не подтвердила или опровергла слухи о том, что Q * — что бы это ни было — на самом деле существует.
Потенциальные последствия "Q"*
По слухам, "Q *" OpenAI может оказать огромное и разнообразное влияние. Если это продвинутая форма Q-learning, это может означать скачок в способности ИИ автономно учиться и адаптироваться в сложных средах, решая совершенно новый набор проблем. Такой прогресс мог бы улучшить приложения искусственного интеллекта в таких областях, как автономные транспортные средства, где решающее значение имеет принятие решений за доли секунды на основе постоянно меняющихся условий.
С другой стороны, если "Q" относится к Q алгоритму MRPPS, это может стать значительным шагом вперед в дедуктивных рассуждениях ИИ и возможностях решения проблем. Это было бы особенно эффективно в областях, требующих глубокого аналитического мышления, таких как юридический анализ, сложная интерпретация данных и даже медицинская диагностика.
Независимо от его точной природы, "Q *" потенциально представляет значительный шаг в развитии ИИ, поэтому тот факт, что он лежит в основе экзистенциальных дебатов OpenAI, звучит правдоподобно. Это могло бы приблизить нас к системам искусственного интеллекта, которые более интуитивно понятны, эффективны и способны решать задачи, которые в настоящее время требуют высокого уровня человеческих знаний. Однако с такими достижениями возникают вопросы и опасения по поводу этики искусственного интеллекта, безопасности и последствий все более мощных систем искусственного интеллекта для нашей повседневной жизни и общества в целом.
Хорошее и плохое в Q*
Потенциальные преимущества Q*:
Улучшенное решение проблем и эффективность: Если Q * является продвинутой формой Q-learning или алгоритма Q *, это может привести к созданию систем искусственного интеллекта, которые решают сложные проблемы более эффективно, принося пользу таким секторам, как здравоохранение, финансы и экологический менеджмент.
Улучшение сотрудничества человека и искусственного интеллекта: Искусственный интеллект с улучшенными способностями к обучению или дедуктивным способностям мог бы улучшить работу человека, что привело бы к более эффективному сотрудничеству в исследованиях, инновациях и повседневных задачах.
Достижения в области автоматизации: "Q *" может привести к появлению более сложных технологий автоматизации, повышению производительности и потенциальному созданию новых отраслей и рабочих мест.
Риски и опасения:
Проблемы этики и безопасности: По мере того, как системы искусственного интеллекта становятся все более совершенными, обеспечение их этичной и безопасной работы становится все более сложной задачей. Существует риск непредвиденных последствий, особенно если действия ИИ не полностью соответствуют человеческим ценностям.
Конфиденциальность и безопасность: С более продвинутым искусственным интеллектом проблемы конфиденциальности и безопасности данных возрастают. Системы искусственного интеллекта, способные к более глубокому пониманию и взаимодействию с данными, могут использоваться не по назначению. Итак, представьте ИИ, который звонит вашему романтическому партнеру, когда вы ему изменяете, потому что он знает, что измена - это плохо.
Экономические последствия: Возросшая автоматизация и возможности искусственного интеллекта могут привести к смене рабочих мест в определенных секторах, что потребует изменений в обществе и новых подходов к развитию рабочей силы. Если ИИ может делать почти все, зачем нужны работники-люди?
Несогласованность ИИ: Риск того, что системы ИИ могут разрабатывать цели или методы работы, которые не соответствуют намерениям человека или благосостоянию, потенциально приводя к вредным результатам. Представьте себе робота-уборщика, который помешан на чистоте и постоянно выбрасывает ваши важные бумаги? Или полностью устраняет создателей беспорядка?
Миф об AGI
Что представляет собой Q * OpenAI, о котором ходят слухи, в погоне за общим искусственным интеллектом (AGI) – святым граалем исследований в области искусственного интеллекта?
AGI относится к способности машины понимать, учиться и применять интеллектуальные данные для решения различных задач, сродни когнитивным способностям человека. Это форма искусственного интеллекта, которая может переносить обучение из одной области в другую, демонстрируя истинную адаптивность и универсальность.
Независимо от того, является ли Q продвинутой формой Q-learning или относится к Q алгоритму, важно понимать, что это не равно достижению AGI. В то время как "Q *" может представлять значительный шаг вперед в конкретных возможностях искусственного интеллекта, AGI охватывает более широкий спектр навыков и понимания.
Достижение AGI означало бы разработку ИИ, способного выполнять любую интеллектуальную задачу, доступную человеку, — труднодостижимая веха.
Машина, достигшая Q, не осознает своего собственного существования и пока не может рассуждать за пределами своих данных предварительной подготовки и алгоритмов, заданных человеком. Так что нет, несмотря на шумиху, “Q” пока не совсем предвестник наших повелителей искусственного интеллекта; это скорее умный тостер, который научился сам намазывать масло на хлеб.
Что касается AGI, предвещающего конец цивилизации, мы, возможно, переоцениваем нашу значимость в космической иерархии. Q * от OpenAI может стать на шаг ближе к ИИ нашей мечты (или ночных кошмаров), но это не совсем тот AGI, который будет размышлять о смысле жизни или своем собственном кремниевом существовании.
Помните, это тот же OpenAI, который с опаской присматривается к своему ChatGPT, как родитель, наблюдающий за малышом с маркером — гордый, но постоянно беспокоящийся, что он нарисует на стенах человечества. В то время как “Q *” - это скачок, AGI остается еще на шаг впереди, и стена человечества на данный момент в безопасности.
Подписывайся на наш Telegram канал. Не трать время на мониторинг новостей. Только срочные и важные новости






 "
"